
Evaluating model fit
For Bayesian diagnostic classification models
Acknowledgements
The research reported here was supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305D210045 to the University of Kansas. The opinions expressed are those of the authors and do not represent the views of the the Institute or the U.S. Department of Education.



The current study
Simulation study to evaluate the efficacy of Bayesian measures of model fit
-
Research questions:
- Do Bayesian measures provide an accurate assessment of model fit?
- How does the accuracy compare to more common methods for assessing model fit (e.g., M2)?
Preprint

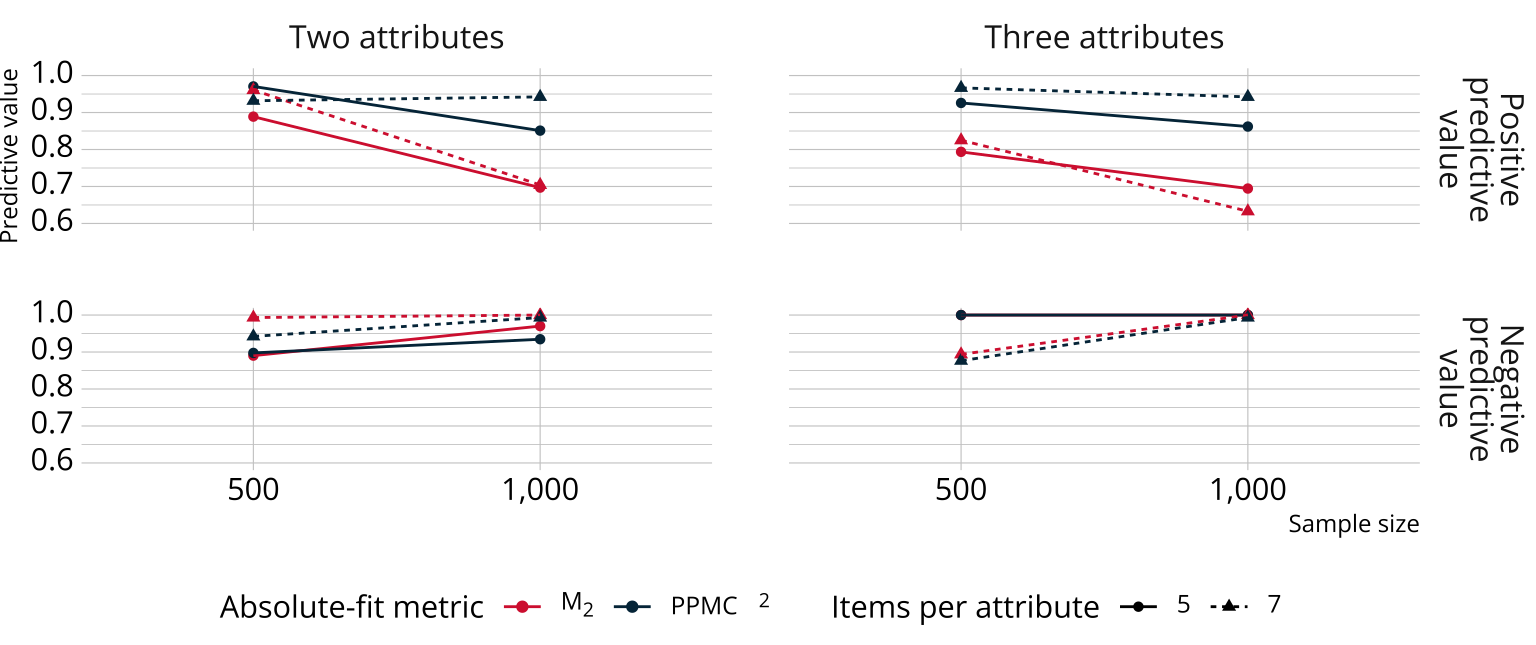
Results: Absolute fit
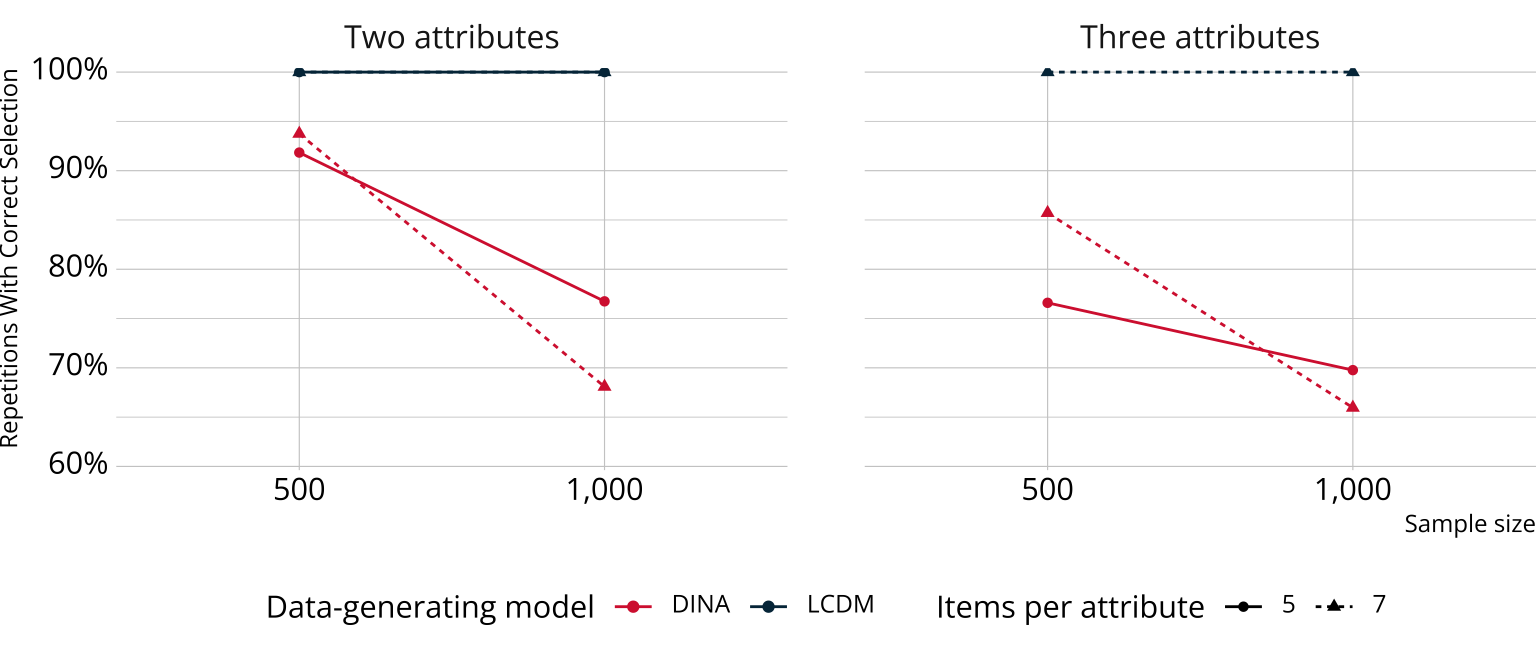
Results: Relative fit
Learn more about measr
Thank you!

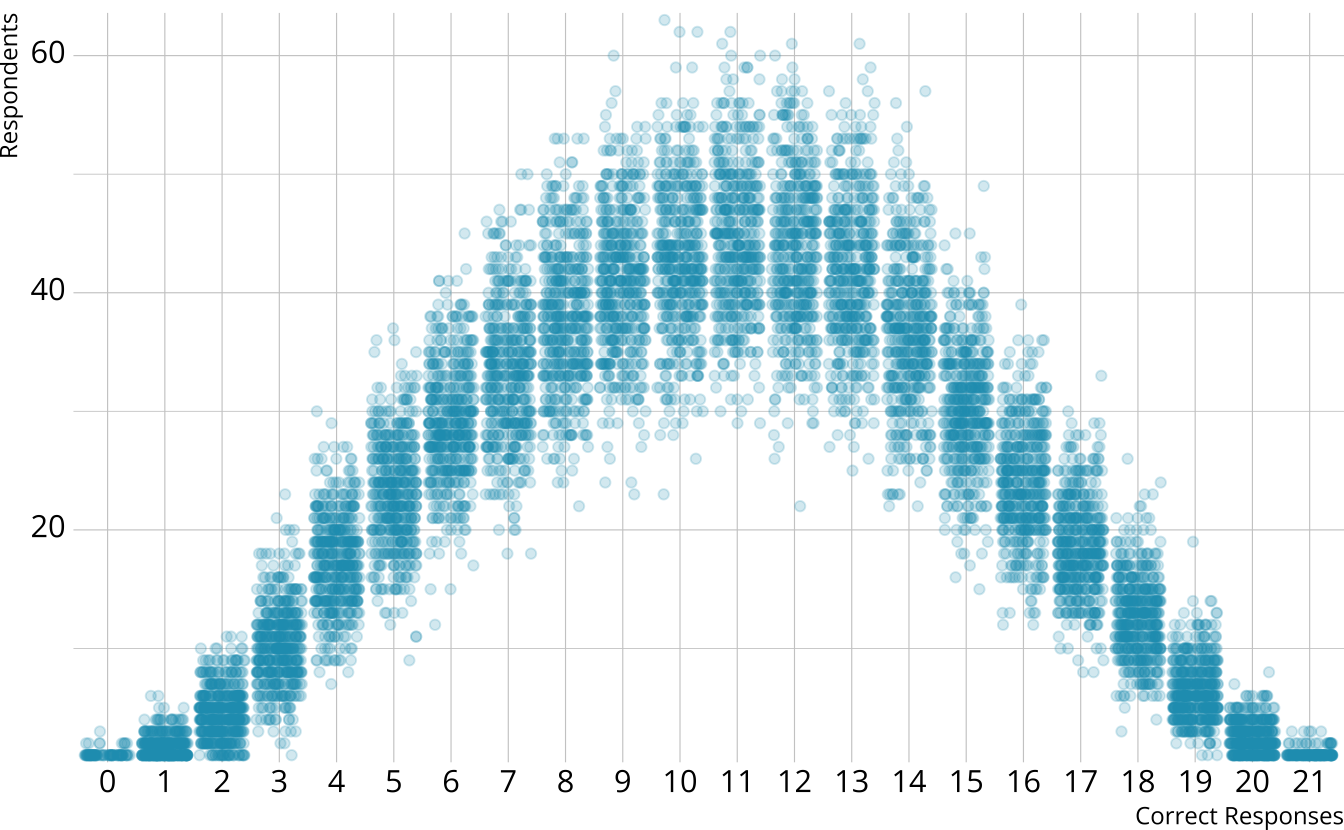
PPMC: Raw score by iteration
- For each iteration, calculate the total number of respondents at each score point
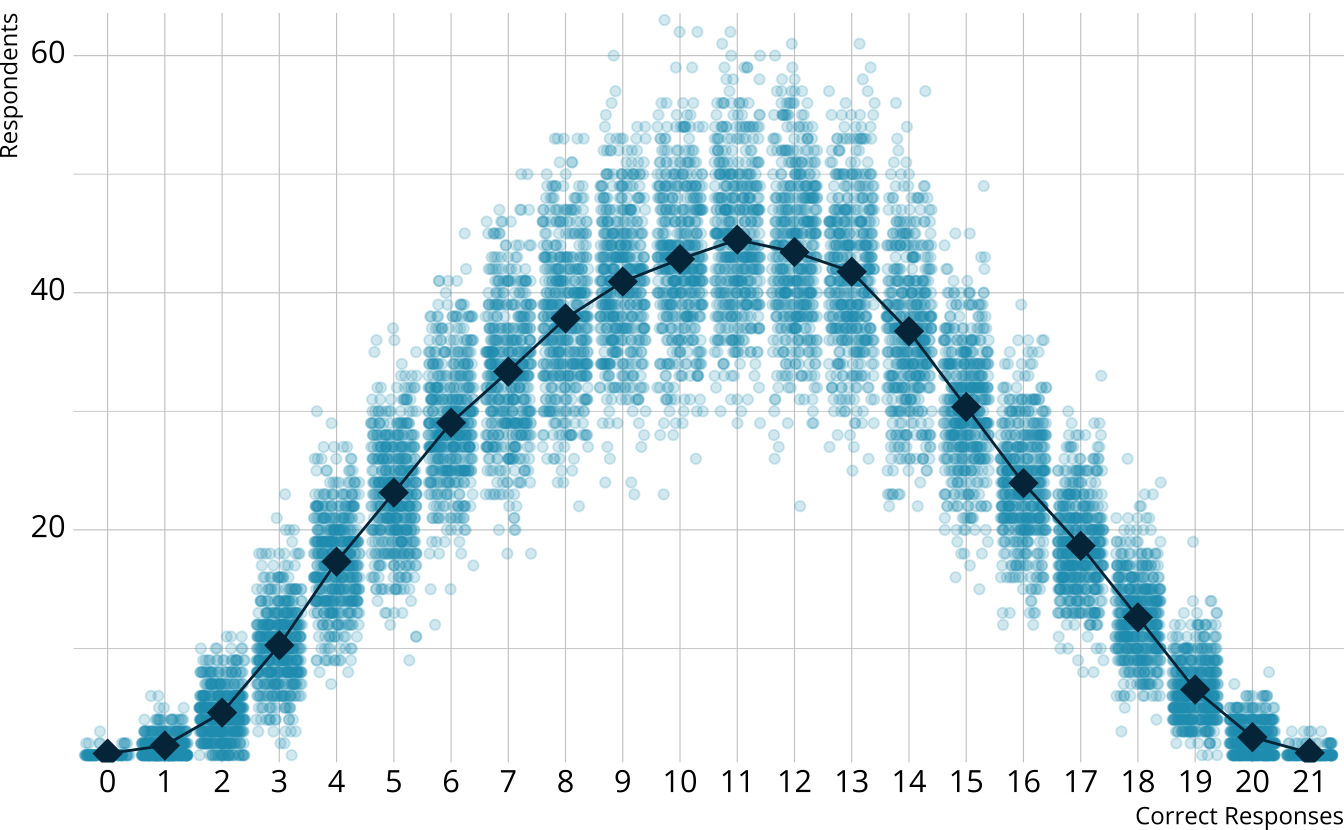
PPMC: Expected counts, by raw score
For each iteration, calculate the total number of respondents at each score point
Calculate the expected number of respondents at each score point
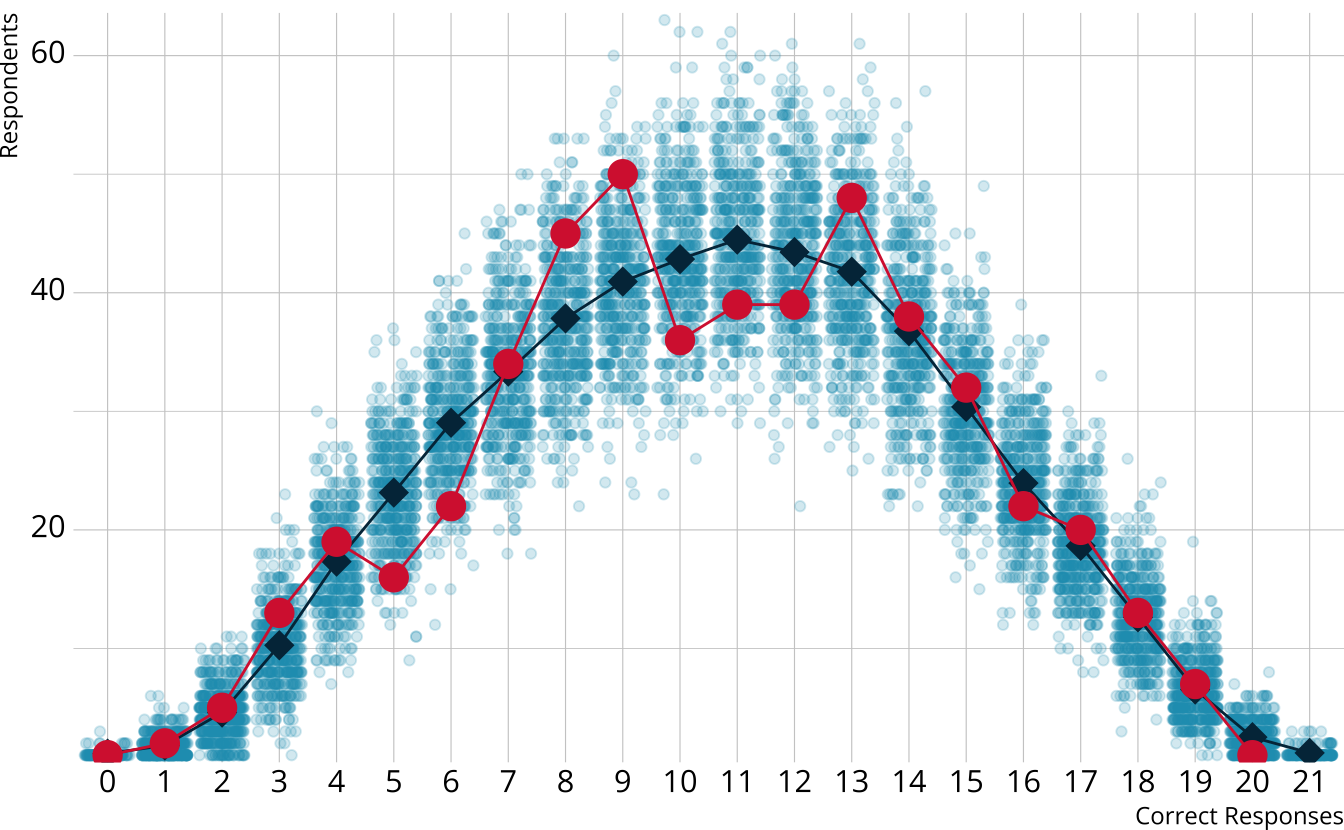
PPMC: Observed counts
For each iteration, calculate the total number of respondents at each score point
Calculate the expected number of respondents at each score point
Calculate the observed number of respondents at each score point
PPMC: χ2 distribution
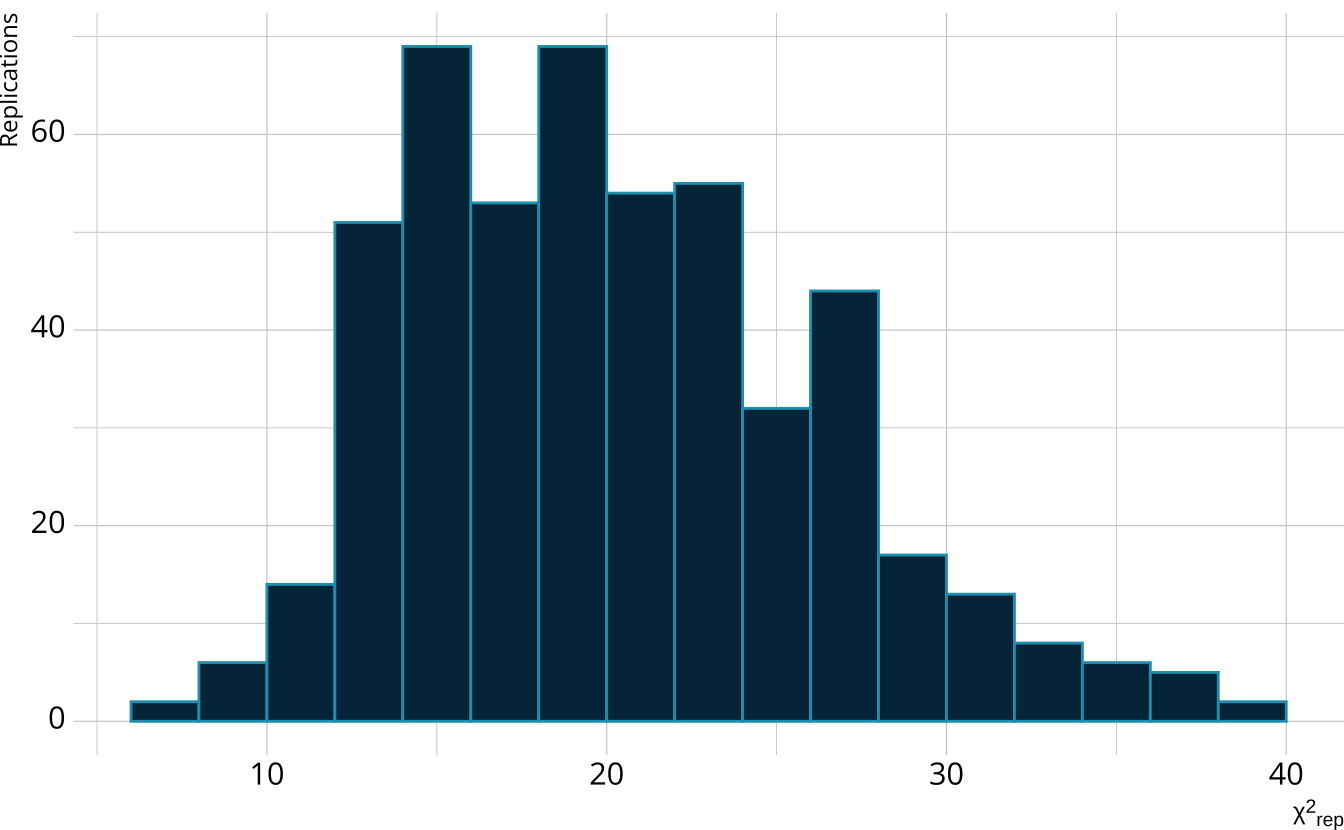
For each replication, calculate a χ2rep statistic
Create a distribution of the expected value of the χ2 statistic
PPMC: χ2 observed value
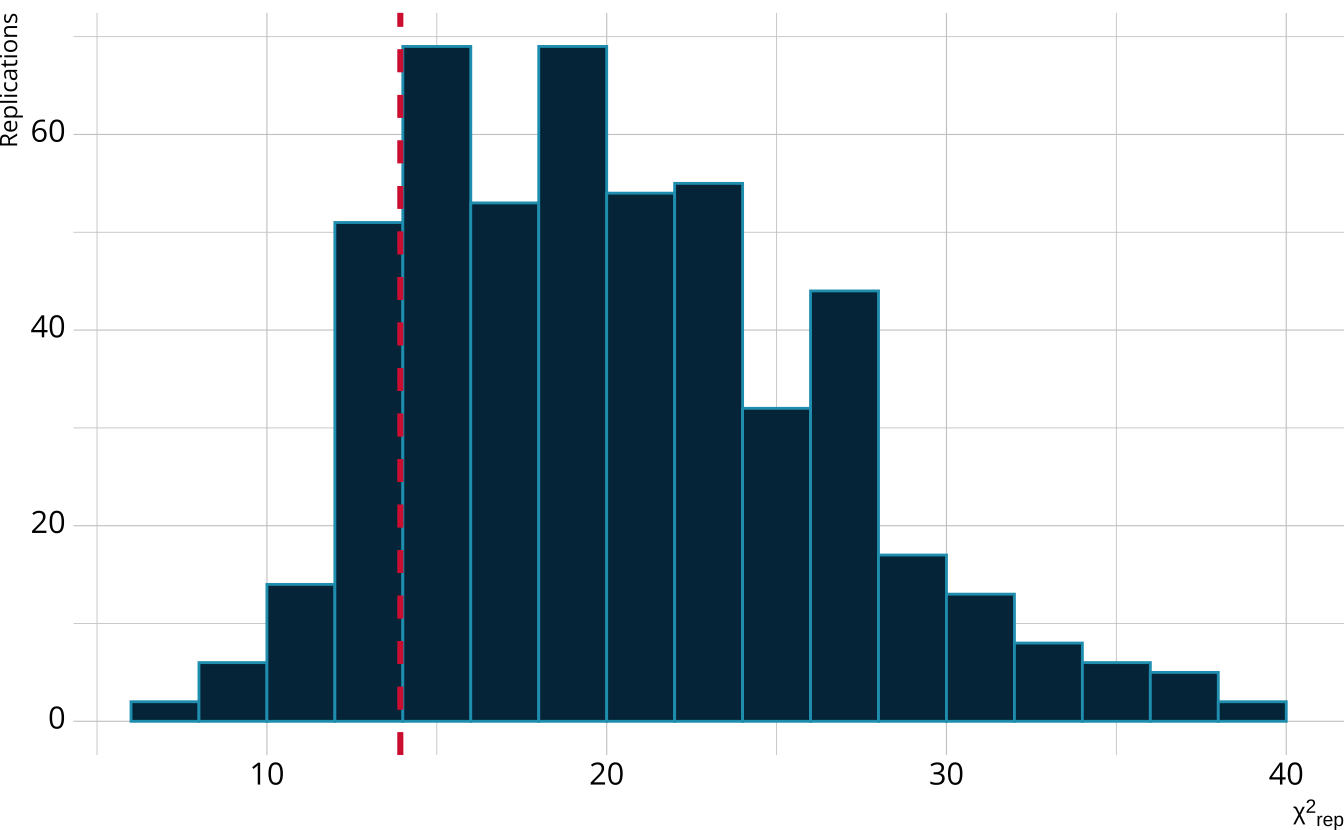
For each replication, calculate a χ2rep statistic
Create a distribution of the expected value of the χ2 statistic
Calculate the χ2 value comparing the observed data to the expectation
PPMC: Posterior predictive p-value
Calculate the proportion of χ2rep draws greater than our observed value
Flag if the observed value is outside a predefined boundary (e.g., .025 < ppp < 0.975)
In our example ppp = 0.856